
Understanding a complex algorithm such as backpropagation can be confusing. You probably have browsed many pages just to find lots of confusing math formulas. Well unfortunately, that’s the way engineers and scientists designed these neural networks. However, there is always a way to port each formula to a program source code.
Porting the Backpropagation Neural Network to C++
In this short article, I am going to teach you how to port the backpropagation network to C++ source code. Please notice I am going to post only the basics here. You will have to do the rest.
First part: Network Propagation
The neural network propagation function is set by -bg-FFFFFF-fg-2B2B2B-s-1.jpg "net=f(\sum\limits_{i=1}^n x_i.w_i + \theta_i.\theta_w)") where net is the output value of each neuron of the network and the f(x) is the activation function. For this implementation, I'll be using the sigmoid function as the activation function. Please notice the training algorithm I am showing in this article is designed for this activation function.
where net is the output value of each neuron of the network and the f(x) is the activation function. For this implementation, I'll be using the sigmoid function as the activation function. Please notice the training algorithm I am showing in this article is designed for this activation function.
Feed forward networks are composed by neurons and layers. So, to make this porting to source code easier, let's take the power of C++ classes and structures, and use them to represent each portion of the neural network with them.
Neural Network Data Structures
A feed forward network as many neural networks, is comprised by layers. In this case the backpropagation is a multi-layer network so we must find the way to implement each layer as a separated unit as well as each neuron. Let’s begin from the simplest structures to the complex ones.
Neuron Structure
The neuron structure should contain everything what a neuron represents:
- An array of floating point numbers as the “synaptic connector” or weights
- The output value of the neuron
- The gain value of the neuron this is usually 1
- The weight or synaptic connector of the gain value
- Additionally an array of floating point values to contain the delta values which is the last delta value update from a previous iteration. Please notice these values are using only during training. See delta rule for more details on /backpropagation.html.
struct neuron
{
float *weights; // neuron input weights or synaptic connections
float *deltavalues; //neuron delta values
float output; //output value
float gain;//Gain value
float wgain;//Weight gain value
neuron();//Constructor
~neuron();//Destructor
void create(int inputcount);//Allocates memory and initializates values
};
Layer Structure
Our next structure is the “layer”. Basically, it contains an array of neurons along with the layer input. All neurons from the layer share the same input, so the layer input is represented by an array of floating point values.
struct layer
{
neuron **neurons;//The array of neurons
int neuroncount;//The total count of neurons
float *layerinput;//The layer input
int inputcount;//The total count of elements in layerinput
layer();//Object constructor. Initializates all values as 0
~layer();//Destructor. Frees the memory used by the layer
void create(int inputsize, int _neuroncount);//Creates the layer and allocates memory
void calculate();//Calculates all neurons performing the network formula
};
The “layer” structure contains a block of neurons representing a layer of the network. It contains the pointer to array of “neuron” structure the array containing the input of the neuron and their respective count descriptors. Moreover, it includes the constructor, destructor and creation functions.
The Neural Network Structure
class bpnet
{
private:
layer m_inputlayer;//input layer of the network
layer m_outputlayer;//output layer..contains the result of applying the network
layer **m_hiddenlayers;//Additional hidden layers
int m_hiddenlayercount;//the count of additional hidden layers
public:
//function tu create in memory the network structure
bpnet();//Construction..initialzates all values to 0
~bpnet();//Destructor..releases memory
//Creates the network structure on memory
void create(int inputcount,int inputneurons,int outputcount,int *hiddenlayers,int hiddenlayercount);
void propagate(const float *input);//Calculates the network values given an input pattern
//Updates the weight values of the network given a desired output and applying the backpropagation
//Algorithm
float train(const float *desiredoutput,const float *input,float alpha, float momentum);
//Updates the next layer input values
void update(int layerindex);
//Returns the output layer..this is useful to get the output values of the network
inline layer &getOutput()
{
return m_outputlayer;
}
};
The “bpnet” class represents the entire neural network. It contains its basic input layer, output layer and optional hidden layers.
Picturing the network structure it isn’t that difficult. The trick comes when implementing the training algorithm. Let’s focus in the primary function bpnet::propagate(const float *input) and the member function layer::calculate(); These functions what they do is to propagate and calculate the neural network output values. Function propagate is the one you should use on your final application.
Calculating the network values
Calculating a layer using the function
Our first goal is to calculate each layer neurons, and there is no better way than implementing a member function in the layer object to do this job. Function layer::calculate() shows how to implement this formula applied to the layer.
void layer::calculate()
{
int i,j;
float sum;
//Apply the formula for each neuron
for(i=0;i<neuroncount;i++)
{
sum=0;//store the sum of all values here
for(j=0;j<inputcount;j++)
{
//Performing function
sum+=neurons[i]->weights[j] * layerinput[j]; //apply input * weight
}
sum+=neurons[i]->wgain * neurons[i]->gain; //apply the gain or theta multiplied by the gain weight.
//sigmoidal activation function
neurons[i]->output= 1.f/(1.f + exp(-sum));//calculate the sigmoid function
}
}
Calculating and propagating the network values
Function propagate, calculates the network value given an input. It starts calculating the input layer then propagating to the next layer, calculating the next layer until it reaches the output layer. This is the function you would use in your application. Once the network has been propagated and calculated you would only take care of the output value.
void bpnet::propagate(const float *input)
{
//The propagation function should start from the input layer
//first copy the input vector to the input layer Always make sure the size
//"array input" has the same size of inputcount
memcpy(m_inputlayer.layerinput,input,m_inputlayer.inputcount * sizeof(float));
//now calculate the inputlayer
m_inputlayer.calculate();
update(-1);//propagate the inputlayer out values to the next layer
if(m_hiddenlayers)
{
//Calculating hidden layers if any
for(int i=0;i<m_hiddenlayercount;i++)
{
m_hiddenlayers[i]->calculate();
update(i);
}
}
//calculating the final statge: the output layer
m_outputlayer.calculate();
}
Training the network
Finally, training the network is what makes the neural network useful. A neural network without training does not really do anything. The training function is what applies the backpropagation algorithm. I'll do my best to let you understand how this is ported to a program.
The training process consist on the following:
- First, calculate the network with function propagate
- We need a desired output for the given pattern so we must include this data
- Calculate the quadratic error and the layer error for the output layer. The quadratic error is determined by
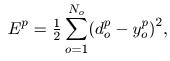 where
where  are the desired and current output respectively
are the desired and current output respectively - Calculate the error value of the current layer by
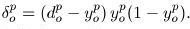 .
. - Update weight values for each neuron applying the delta rule
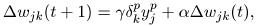 where
where  is the learning rate constant
is the learning rate constant  the layer error and the layer input value. is the learning momentum and is the previous delta value.
the layer error and the layer input value. is the learning momentum and is the previous delta value.
The next weight value would be - Same rule applies for the hidden and input layers. However, the layer error is calculated in a different way.
.\sum\limits_{i-1}-n lerror_l . w_l-bg-FFFFFF-fg-2B2B2B-s-1.jpg "lerror_c=nout_c * (1-nout_c).\sum\limits_{i=1}^n lerror_l . w_l") where
where  and
and  are the error and weight values from the previous processed layer. is the output of the neuron currently processed
are the error and weight values from the previous processed layer. is the output of the neuron currently processed
//Main training function. Run this function in a loop as many times needed per pattern
float bpnet::train(const float *desiredoutput, const float *input, float alpha, float momentum)
{
//function train, teaches the network to recognize a pattern given a desired output
float errorg=0; //general quadratic error
float errorc; //local error;
float sum=0,csum=0;
float delta,udelta;
float output;
//first we begin by propagating the input
propagate(input);
int i,j,k;
//the backpropagation algorithm starts from the output layer propagating the error from the output
//layer to the input layer
for(i=0;i<m_outputlayer.neuroncount;i++)
{
//calculate the error value for the output layer
output=m_outputlayer.neurons[i]->output; //copy this value to facilitate calculations
//from the algorithm we can take the error value as
errorc=(desiredoutput[i] - output) * output * (1 - output);
//and the general error as the sum of delta values. Where delta is the squared difference
//of the desired value with the output value
//quadratic error
errorg+=(desiredoutput[i] - output) * (desiredoutput[i] - output) ;
//now we proceed to update the weights of the neuron
for(j=0;j<m_outputlayer.inputcount;j++)
{
//get the current delta value
delta=m_outputlayer.neurons[i]->deltavalues[j];
//update the delta value
udelta=alpha * errorc * m_outputlayer.layerinput[j] + delta * momentum;
//update the weight values
m_outputlayer.neurons[i]->weights[j]+=udelta;
m_outputlayer.neurons[i]->deltavalues[j]=udelta;
//we need this to propagate to the next layer
sum+=m_outputlayer.neurons[i]->weights[j] * errorc;
}
//calculate the weight gain
m_outputlayer.neurons[i]->wgain+= alpha * errorc * m_outputlayer.neurons[i]->gain;
}
for(i=(m_hiddenlayercount - 1);i>=0;i--)
{
for(j=0;j<m_hiddenlayers[i]->neuroncount;j++)
{
output=m_hiddenlayers[i]->neurons[j]->output;
//calculate the error for this layer
errorc= output * (1-output) * sum;
//update neuron weights
for(k=0;k<m_hiddenlayers[i]->inputcount;k++)
{
delta=m_hiddenlayers[i]->neurons[j]->deltavalues[k];
udelta= alpha * errorc * m_hiddenlayers[i]->layerinput[k] + delta * momentum;
m_hiddenlayers[i]->neurons[j]->weights[k]+=udelta;
m_hiddenlayers[i]->neurons[j]->deltavalues[k]=udelta;
csum+=m_hiddenlayers[i]->neurons[j]->weights[k] * errorc;//needed for next layer
}
m_hiddenlayers[i]->neurons[j]->wgain+=alpha * errorc * m_hiddenlayers[i]->neurons[j]->gain;
}
sum=csum;
csum=0;
}
//and finally process the input layer
for(i=0;i<m_inputlayer.neuroncount;i++)
{
output=m_inputlayer.neurons[i]->output;
errorc=output * (1 - output) * sum;
for(j=0;j<m_inputlayer.inputcount;j++)
{
delta=m_inputlayer.neurons[i]->deltavalues[j];
udelta=alpha * errorc * m_inputlayer.layerinput[j] + delta * momentum;
//update weights
m_inputlayer.neurons[i]->weights[j]+=udelta;
m_inputlayer.neurons[i]->deltavalues[j]=udelta;
}
//and update the gain weight
m_inputlayer.neurons[i]->wgain+=alpha * errorc * m_inputlayer.neurons[i]->gain;
}
//return the general error divided by 2
return errorg / 2;
}
Sample Application
The complete source code can be found at the end of this article. I also included a sample application that shows how to use the class "bpnet" and how you may use it on an application. The sample shows how to teach the neural network to learn the XOR (or exclusive) gate.
There isn't much complexity to create any application.
#include <iostream>
#include "bpnet.h"
using namespace std;
#define PATTERN_COUNT 4
#define PATTERN_SIZE 2
#define NETWORK_INPUTNEURONS 3
#define NETWORK_OUTPUT 1
#define HIDDEN_LAYERS 0
#define EPOCHS 20000
int main()
{
//Create some patterns
//playing with xor
//XOR input values
float pattern[PATTERN_COUNT][PATTERN_SIZE]=
{
{0,0},
{0,1},
{1,0},
{1,1}
};
//XOR desired output values
float desiredout[PATTERN_COUNT][NETWORK_OUTPUT]=
{
{0},
{1},
{1},
{0}
};
bpnet net;//Our neural network object
int i,j;
float error;
//We create the network
net.create(PATTERN_SIZE,NETWORK_INPUTNEURONS,NETWORK_OUTPUT,HIDDEN_LAYERS,HIDDEN_LAYERS);
//Start the neural network training
for(i=0;i<EPOCHS;i++)
{
error=0;
for(j=0;j<PATTERN_COUNT;j++)
{
error+=net.train(desiredout[j],pattern[j],0.2f,0.1f);
}
error/=PATTERN_COUNT;
//display error
cout << "ERROR:" << error << "\r";
}
//once trained test all patterns
for(i=0;i<PATTERN_COUNT;i++)
{
net.propagate(pattern[i]);
//display result
cout << "TESTED PATTERN " << i << " DESIRED OUTPUT: " << *desiredout[i] << " NET RESULT: "<< net.getOutput().neurons[0]->output << endl;
}
return 0;
}
Download the source as ZIP File here. Please notice this code is only for educational purposes and it's not allowed to use it for commercial purposes.
UPDATE: Source code is available on GitHub too here is the link https://github.com/danielrioss/bpnet_wpage
thank you so much for sharing ur precious information
Your very welcome. Thanks for stopping by.
i want some problem based on back propagation network using Matlab code with arachitecture
thanks
Thank you for sharing out your knowledge, I so much appreciate.
Thank you James for stopping by. I am glad I could help.
I replaced the binary sigmoid function with the bipolar one: neurons[i]->output = (1.f - exp(-sum)) / (1.f + exp(-sum)); so the input data could be in the interval [-1, 1] rather than [0, 1]. I’ve also updated the radom() for the initial weights. Still when I run the program, I get a lot of “nan” (infinity) instead of real numbers for outputs. What am I doing wrong? Is the error calculation going to be different?
Hello Justin, thank you for stopping by. Are those errors after the modification or before?
Unfortunately, the algorithm I am showing up there only works for the sigmoid function as it is closely related to the training algorithm.
An addition to my prev comment…
Under the “training” loop, the output is as following:
ERROR: 0.713038
ERROR: 1.17499
ERROR: 1.24992
ERROR: 1.25
ERROR: 1.25
ERROR: 1.25
ERROR: 1.25
ERROR: 1.25
ERROR: 1.25
ERROR: nan
ERROR: -nan
ERROR: -nan
ERROR: -nan
…
Also, how would you make your algorithm multi-threaded?
On a different forum I read this: “Basically I create a number of threads and divide up the training data so each thread has a near equal amount. Then at regular intervals I merge the weights back together from the independent threads.”
How would you merge the weights back togehter?
Actually, I have developed a library that works with multithreading.
I posted here the basics to show in the most simplistic way the algorithm.
I hope I can post it here soon.
But basically if you want to do it multithreading this is the way to do it:
Take the layer in process and assign a group of neurons of the same layer to each thread:
For example if you have 30 neurons and you are using 4 threads for processing: then you would assign 7 neurons per thread, and reassign to the first ending thread the two lasting neurons. And leave waiting all threads that ended their process until the last finish.
Once you have processed the current layer you move to the next one:
Update the next layer inputs and make the same process as with the last layer: Assign neurons to process to each thread..
..until you reach the output layer.
This actually takes all the power of your CPU and increases speed.
How would you change your algorithm to make it resilient back-propagation (RPROP)?
I once implemented backprop in oracle pl/sql.
hey please post or send back propagation algorithm in Matlab if available…….
Hello, you can easily change the code to matlab, I think the code is quite clear.
pls tell me how can i change code in matlab or pls mail me the matlab code.
I’ll try to post the mathlab code as soon I have time to do it. Best Regards.
Hello
im mohsen fron iran
I can not download the source of code for Backpropagation Algorithm into C++.
can you sen me?
do you have the source code for learning a sin function in neural network?
thanks very much.
Hi, could you explain me on what depends the wgain value. It should be a positive or negative number?
Thank you for your great tutorial 🙂
Hello, Andre my apologies for my very delayed answer. The value wgain is the weight value for the bias according to the net formula-bg-FFFFFF-fg-2B2B2B-s-1.jpg "net=f(\sum\limits_{i=1}^n x_i.w_i + \theta_i.\theta_w)") . Pretty much is yet another weight that modifies the bias value .
. Pretty much is yet another weight that modifies the bias value .
It is initialized as random. In this source code all weights are initialized on a range from -0.5 to 0.5 so it does not matter the sign.
Most clear backprop tutorial I have read (out of 10 or so). Excellent.
I am glad I could help
Hello.
thank you for the information sir, i have a question.
I want to put more Network inputs and Network outputs(like 5 or 10 more)
#define NETWORK_INPUTNEURONS 10
#define NETWORK_OUTPUT 10
but i dont know how can i display the result of the ouputs when they are more than 1
//display result
cout << "TESTED PATTERN " << i << " DESIRED OUTPUT: " << *desiredout[i] << " NET RESULT: " <output << endl;
//}
Do i have to modify just the previous line of code or there is more to modify than just that ?
Thanks in advance.
Nvm : i Just found the solution
Thanks.
When i try to use 1 hidden layer i get this error:
errorC2664: ‘void bpnet::create(int,int,int,int *,int)’ : cannot convert argument 4 from ‘int’ to ‘int *’
can you tell me how to fix it ?
Thanks
you are getting this error because parameter 4 needs you to put a a pointer to an array of integer values which in this case is the neuron count per hidden layer and parameter 5 the total count of hidden layers.
In this case you want 1 hidden layer
you should do something like this
#define HIDDEN_LAYER_COUNT 1 int hiddenlayerNeuronCount[HIDDEN_LAYER_COUNT]={layer_neuron_count}; int hiddenlayercount=HIDDEN_LAYER_COUNT; net.create(input_size,input_neuron_count,output_count,hiddenLayerNeuronCount,hiddenlayercount);if you want more layers, increase HIDDEN_LAYER_COUNT and specify the count of neurons per hiddenlayer. Each element of the array would be the neuron count per hiddenlayer.
Thank you sir.
Can you tell me how can i now the neuron count per layer in this part
int hiddenlayerNeuronCount[HIDDEN_LAYER_COUNT]={layer_neuron_count};
i dont know what number or variable to use instead of “layer_neuron_count”
Sir basically I am control engineer. I want to develop expertise in the area of neurofuzzy control. I have background in fuzzy however i am new to neural networks. I just learned gradient descent rule and how it can adjust weights to reach the minima and a bit of back propagation algorithm . But the problem is that I read lot of stuff, all of them are trying to use mathematical language.I appreciate their effort but now I want to program for example a neural network which I can train with gradient descent for any thing let say to find the coefficients of a reference linear function.Please recommend me some book which can take me step wise by giving me the basic understanding of different networks , implementation in matlab and applications and so on and so forth. I dont have words for the contribution which you are doing in terms of imparting knowledge and helping students.
The best book I can recommend you is: Neural Networks Algorithms, Applications and Programming Techniques…It is quite old but shows the basics of neural networks with some code examples.
Thank you. I will look into the link. Also can you advise me on the matlab version of this code. At the moment I am focusing on Gradient descent and back propagation. Finally I want to develop a Neurofuzzy controller for speed control of motor
Unfortunately, I don’t have the matlab version of this code. It is not the first time people requested it to me. Porting this C++ code to Matlab isn’t difficult.
Thank you, I just jumped into matlab and started to write my own code.At the moment I am just following my rough understanding what i read in the books in the following way for two inputs and single hidden layer.
1) two inputs x1 and x2
2) weights like w1,……..,w4 between inputs and layer 1.
3) output of two neuron in the hidden layer
o1=sigmoid(x1w1+x2w3)
o2=sigmoid(x2w4 + x1w2)
4) simillarly weights between the hidden layer and the output. and finally output neurons.
5) Finally i will calculate the error by the difference of desired and actual output.
6) finally i will try to implement the equation of the update rule for weights.
7) The only way i know is gradient descent. I will try that
8) But what is the difference between LMS,NLMS and gradient descent. I think all of them are doing the same thing.Please correct me.
9) Incase i found some problems i will come back to you.
7)
Hello sir,
I’m doing character recognition using back propagation in java for my PG degree project. The letters are not recognized properly and i’m unable to sort the mistake. Can u help me by some sample code for character recognition. Else i want a clear step by step procedure for character recognition using back propagation. I’m using the binary data as input and output.
I have small project using this code for character recognition. Unfortunately, I have not had the time to post it. I’ll let you know when I have it.
Thanks u sir…
Sir,
Why do u calculate the input layer?the input layer is calculated with multiplication with random weights and then sigmoid used.isn’t this wrong as only the inputs should be propagated to the hidden layer?
That’s what I do there, multiply the input with neuron weights and then pass them to the sigmoid function. If you set random weights each time you calculate the input layer then the training on that layer would be in bane, because you would be overwriting the weights of the input layer that have been trained.
Please check the code and you’ll see weights are initialized as random when the network is created. Later those weights are adjusted by the training function.
Function:
does exactly what you said. It multiplies the weights of the layer with the input of it and pass it to sigmoid function.
Hi there, thanks a lot for sharing your code and so detailed explanation! It is so clear! Really appreciate it!
I have a question. With the same XOR example, I changed the desired out to be
NETWORK_OUTPUT=2;
PATTERN_COUNT=4;
float desiredout[PATTERN_COUNT][NETWORK_OUTPUT]=
{
{0,1},
{1,0},
{1,0},
{0,1}
};
And the result is not right anymore.
Could you help me? Thanks!!
Hi there, when you change the output or input size and you don’t get the result you want, you have to change some parameters of the network.
I tested the network with the default parameters and yes, it wasn’t converging. So I tested different neuron counts on the input layer and even added a hidden layer and came up with the solution.
I basically added more neurons to the input layer to make a total of 6 and increased training iterations.
I tried with different input neuron counts and 6 was the perfect solution. Even 5 was not converging. Moreover I had to increase training epochs.
Unfortunately, there is no formula to find out the perfect network configuration for a given problem. You have to test different configurations until you find the solution.
Hi there, I have another question on the back-prop. It is about calculating gradient from output layer to hidden layer.
Would you refer this link? It is about equation (18).
http://www.speech.sri.com/people/anand/771/html/node37.html
According to the equation (18), for each hidden neuron, the sum sign is summing all output neurons that are connected to one hidden neuron. According to your code, in the “train()” method, the variable “sum” is summing all connections between any two neurons between hidden layer and output layer.
Did I understand right? I would really appreciate if you could answer my questions. Thanks!
Yes that’s right, the variable “sum” is used to calculate the gradient of the hidden layer.
Hello,
I tried your application and I have weird results when I add hidden layers for non linearly separable data. For example I have 150 patterns each with 2 values from range 0..1 and 3 outputs (0 or 1). I add one hidden layer which contains 3 neurons and almost all test fails.
I tried write backpropagation algorithm myself based on this article and I got the same result.
I noticed that problem is with weights. In my case in first epoch they values are around 0.9. After 500 epochs weights values is around 190! This makes sum of weight*input really high and sigmoid function returns value close to 1.
Could you give me some advice what can I do?
Hello, for most cases it is the best to have only the input and output layers..if your application does not converge you can adjust the quantity of neurons of the input layer….starting with the lowest value and start rising them until you get some results. Can you give me more details about your application so I can reproduce myself? Feel free to send me an email with details at daniel dot rios at learnartificialneuralnetworks dot com at any time.
#include #include #include main() { float wa1=.1,wa2=.4,wb1=.8,wb2=.6,wd1=.3,wd2=.9; float inputA=.35,inputB=.9; float t=.5; int c=0; float inputUpperNode=(wa1*inputA)+(wb1*inputB); printf("Input for Upper Node = %f", inputUpperNode); printf("\n\n"); float inputLowerNode=(wa2*inputA)+(wb2*inputB); printf("Input for Lower Node = %f", inputLowerNode); printf("\n\n"); float outputUpperNode=1/(1+(exp(-((wa1*inputA)+(wb1*inputB))))); printf("Output for Upper Node = %f", outputUpperNode); printf("\n\n"); float outputLowerNode=1/(1+(exp(-((wa2*inputA)+(wb2*inputB))))); printf("Output for Lower Node = %f", outputLowerNode); printf("\n\n"); float inputFinalNode=(outputUpperNode*wd1)+(outputLowerNode*wd2); printf("Input For Final Node = %f", inputFinalNode); printf("\n\n"); float outputFinalNode=1/(1+(exp(-((outputUpperNode*wd1)+(outputLowerNode*wd2))))); printf("Output For Final Node = %f",outputFinalNode); printf("\n\n"); float outputError=(t-outputFinalNode)*(1-outputFinalNode)*outputFinalNode; printf("Output Error = %.3f",outputError); printf("\n\n"); while(outputFinalNode!=t) { wd1=wd1+(outputError*outputUpperNode); printf("new Weight of wd1 = %f ",wd1); wd2=wd2+(outputError*outputLowerNode); printf("new Weight of wd2 = %f",wd2); float outputErrorUpperNode=(outputError*wd1)*(1-outputUpperNode)*outputUpperNode; printf("Output Error for Upper Node = %f",outputErrorUpperNode); float outputErrorLowerNode=(outputError*wd2)*(1-outputLowerNode)*outputLowerNode; printf("Output Error for Lower Node = %f",outputErrorLowerNode); wa1=wa1+(outputErrorUpperNode*inputA); printf("New Weight of A for Upper Node = %f",wa1); wa2=wa2+(outputErrorLowerNode*inputA); printf("New Weight of A for Lower Node = %f",wa2); wb1=wb1+(outputErrorUpperNode*inputB); printf("New Weight of B for Upper Node = %f",wb1); wb2=wb2+(outputErrorLowerNode*inputB); printf("New Weight of B for Lower Node = %f",wb2); inputUpperNode=(wa1*inputA)+(wb1*inputB); printf("Input for Upper Node = %f",inputUpperNode); inputLowerNode=(wa2*inputA)+(wb2*inputB); printf("Input for Lower Node = %f",inputLowerNode); outputUpperNode=1/(1+(exp(-((wa1*inputA)+(wb1*inputB))))); printf("Output For Upper Node = %f",outputUpperNode); outputLowerNode=1/(1+(exp(-((wa2*inputA)+(wb2*inputB))))); printf("Output For Lower Node = %f",outputLowerNode); inputFinalNode=(outputUpperNode*wd1)+(outputLowerNode*wd2); printf("Input For Final Node = %f",inputFinalNode); outputFinalNode=1/(1+(exp(-((outputUpperNode*wd1)+(outputLowerNode*wd2))))); printf("Output For Final Node = %f",outputFinalNode); outputError=(t-outputFinalNode)*(1-outputFinalNode)*outputFinalNode; printf("Output Error = %f",outputError); c++; } printf("c = %d",c); return 0; }why this is going to infant time